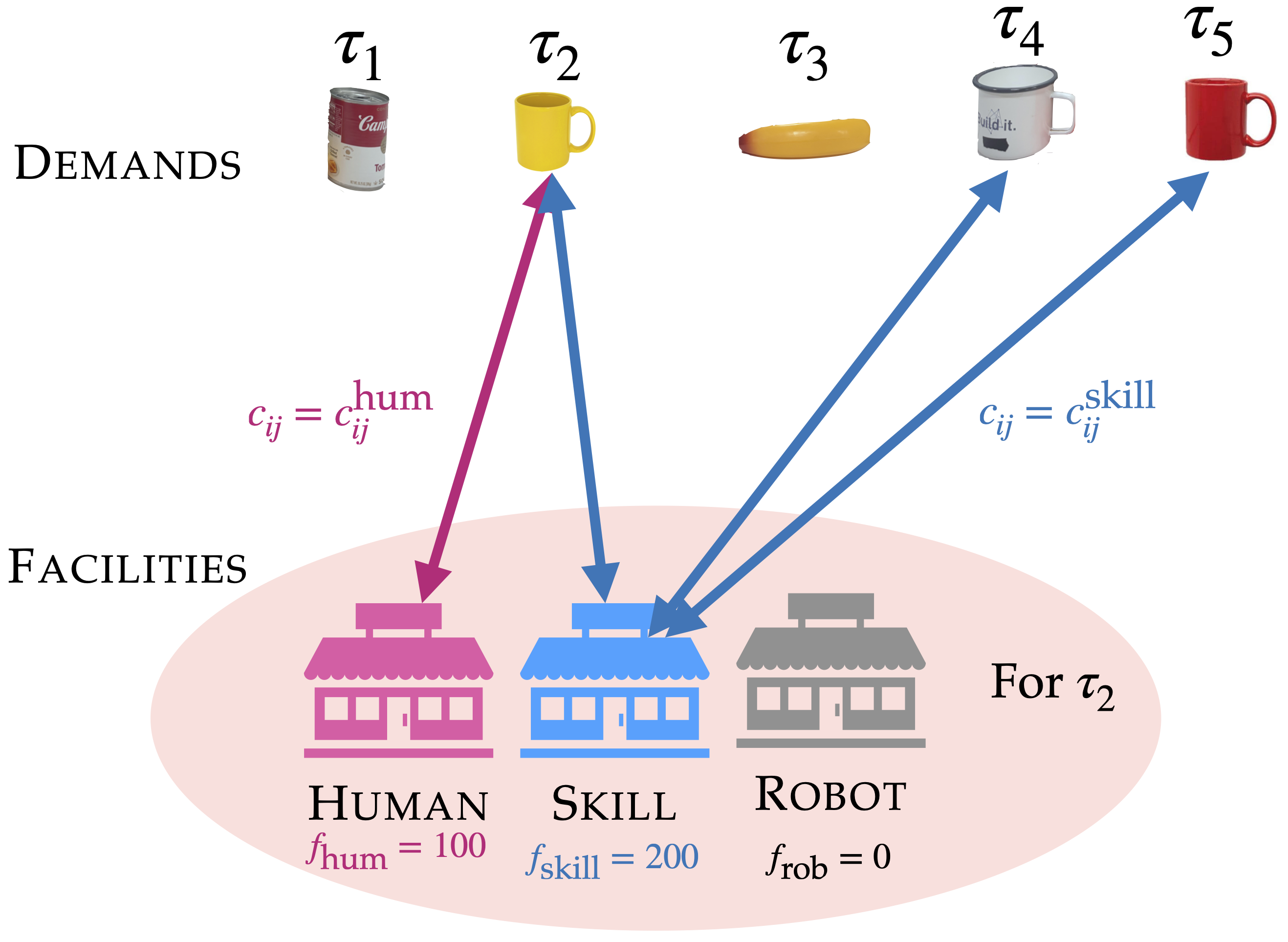
Facility location formulation. Tasks 𝛕 are demands to be satisfied. Facilities correspond to interactive actions available for every task. We highlight facilities for 𝛕2: Human facility can only service 𝛕2. Skill facility can service similar future tasks 𝛕2, 𝛕3, 𝛕4. Robot facility cannot service any task as the robot hasn't learned a skill yet. Furthermore, none of the facilities can service past tasks.
Results: Gridworld Domain
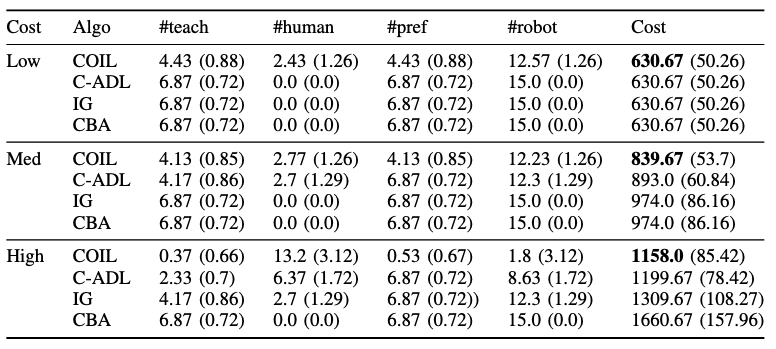
In the Gridworld domain, we find that COIL makes fewer preference queries than the confidence-based baselines because COIL only asks for human preferences if it believes that this information will be useful later. Format is mean(standard deviation).
Results: Manipulation Domain
Results on the manipulation domain. On average, COIL plans interactions that result in 7% to 18% reduction in cost compared to the best performing baseline. The improvement over baselines is particularly marked when the cost of teaching is more expensive than assigning the task to the human, i.e, medium and high cost profiles. The reported statistics are averaged over 10 interactions with 30 randomly sampled tasks each.
Results: Real World Conveyor Belt Domain
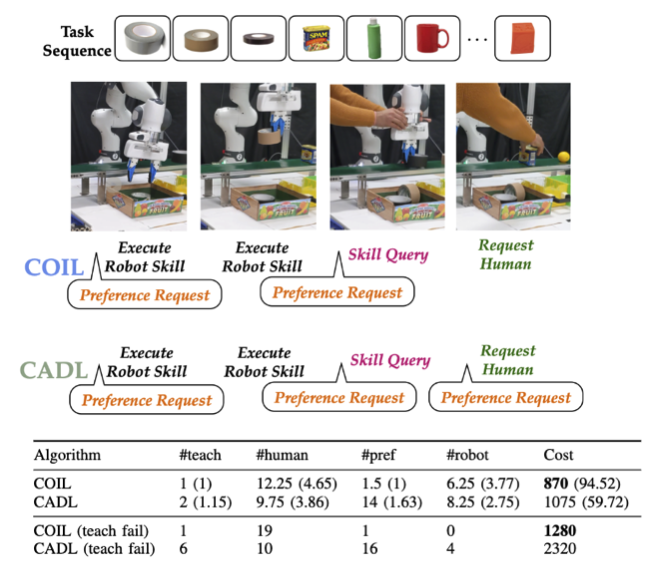
Results on a physical conveyor. We ran experiments with 5 different task sequences, each with 20 objects, with COIL and CADL. We observed teaching failure on the white mug (pos- sibly because its shiny surface made camera-based pose estimation difficult). Hence, we report the run with teaching failure separately from the other 4 runs. COIL was able to achieve significantly lower cost than the baseline in both situations. CADL especially struggled in the case of teaching failure as it repeatedly requested to be taught the mug skill.
BibTeX
@article{vats2025optimal,
title={Optimal Interactive Learning on the Job via Facility Location Planning},
author={Vats, Shivam and Zhao, Michelle and Callaghan, Patrick and Jia, Mingxi and Likhachev, Maxim and Kroemer, Oliver and Konidaris, George},
journal={Robotics: Systems and Science},
year={2025}
}